



The English Speech Corpus with Different Proficiency Levels was officially launched in March 2021 by Dr Rebecca Chen from the Department of Linguistics and Modern Language Studies of the Education University of Hong Kong. The English Speech Corpus with Different Proficiency Levels aims to provide learners, teachers and researchers with high-quality authentic recordings from practice tests and detailed annotations of linguistic features of English learners. With the help of the data, English learners can identify difficulties in English speaking learning.
The corpus contains 78 sets of spontaneous speech data and 13 sets of classroom presentation data with detailed linguistic annotations that focus on four aspects of Fluency and Coherence, Lexical Resource, Grammatical Range and Accuracy and Pronunciation. In the corpus, users can select different features that facilitate their learning, such as self-correction, paraphrases, vowel features, and grammatical errors. Of the 78 sets of data, 48 are collected from mainland China and Hong Kong learners, and 30 are retrieved from IELTS speaking official videos.
To find a specific data, users can use either “Browse” or “Search” function. In “Browse” function, users can browse speech data with or without filters. Users can also use “Search” function to search the recording samples by selecting the linguistic features and setting different criteria you are interested in.
Please click hereto The English Speech Corpus with Different Proficiency Levels.
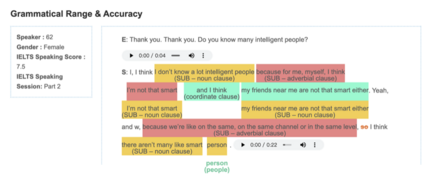
The annotations of the speaker’s performance in grammatical range and accuracy
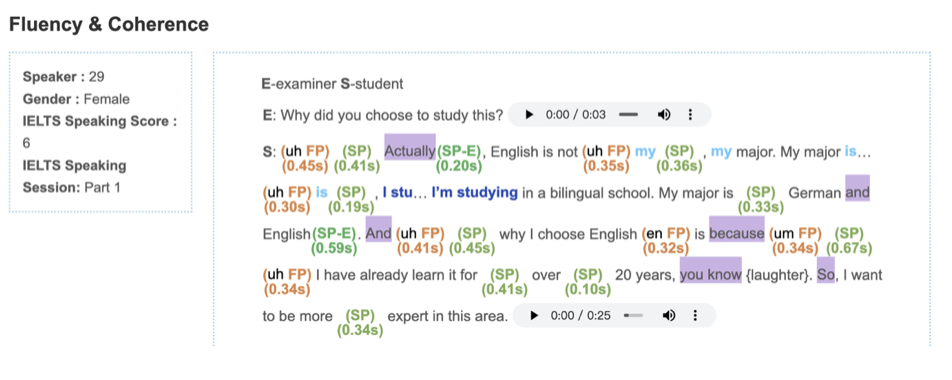
The annotations of the speaker’s performance in fluency and coherence